6. Primary Memory
Primary memory is the computer's working area. It stores data and instructions that the CPU needs immediately. Efficient primary memory is crucial for high system performance. It consists of Registers, Cache, RAM, and ROM.
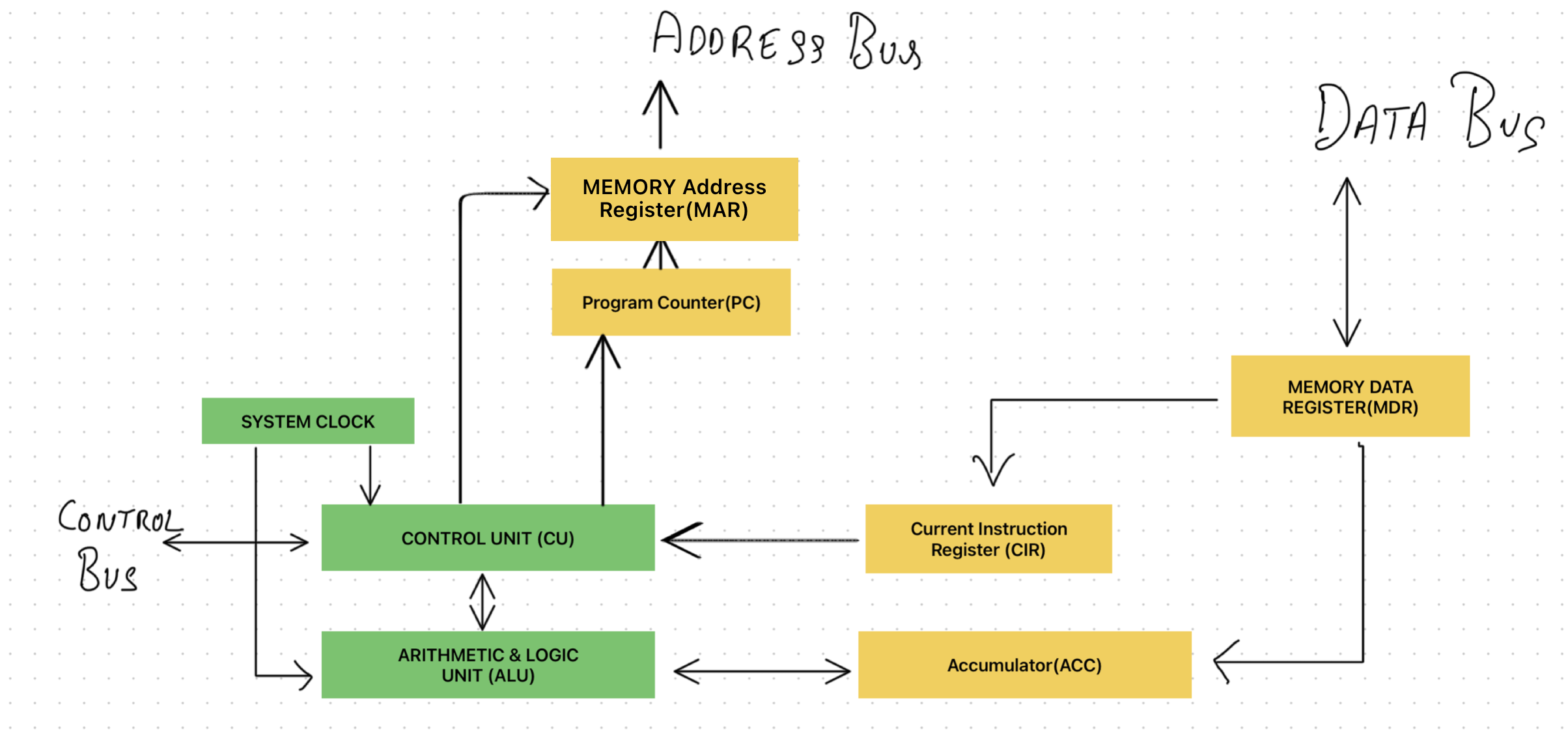
Registers
Small, super-fast memory locations inside the CPU. They hold data temporarily while instructions are being executed.
RAM (Random Access Memory)
RAM is the computer's temporary workspace where data and programs are stored while the computer is running. Think of it as the computer's "desk".
- Stores active programs: When you open an app, it loads into RAM for quick CPU access.
- Holds data being processed: The CPU reads/writes data to RAM during calculations.
- Enables multitasking: Multiple programs run simultaneously by sharing RAM space.
- Volatile: Data is lost when power is off.
- Fast access: Much faster than secondary storage (HDD/SSD).
DRAM vs. SRAM
| Aspect | DRAM (Dynamic RAM) | SRAM (Static RAM) |
|---|---|---|
| How it works | Uses capacitors (needs constant refreshing). | Uses flip-flops (no refreshing needed). |
| Speed | Slower (50-100 ns) | Faster (1-10 ns) |
| Cost & Density | Cheaper, Higher Density (Main Memory) | Expensive, Lower Density (Cache) |
| Usage | Main System RAM | CPU Cache (L1, L2, L3) |
ROM (Read-Only Memory)
ROM stores permanent, essential instructions needed for startup (Non-volatile).
- Stores BIOS: Fundamental instructions to initialize hardware.
- Boot Process: Tells the CPU how to load the OS from the hard drive.
- Non-volatile: Retains data even when the computer is turned off.
- Read-Only: Cannot be easily modified by users.
Interaction between CPU and Memory
Cache Memory (L1, L2, L3)
Cache memory serves as a high-speed intermediary between the CPU and the slower main memory (RAM). It is divided into levels (L1, L2, L3) based on proximity to the CPU, with L1 being the smallest and fastest, and L3 being larger and slightly slower but still faster than RAM.
Modern CPUs use sophisticated algorithms to predict which data and instructions will be needed soon, and pre-emptively load them into the cache. This anticipatory action reduces the time the CPU spends waiting for data, thus optimizing performance.
Caches exploit the principles of spatial locality (data near recently accessed data is likely to be accessed soon) and temporal locality (recently accessed data is likely to be accessed again soon) to keep relevant data close at hand.
Main Memory (RAM)
RAM holds the operating system, applications, and data that are currently in use. It provides a much larger space for data storage compared to caches and registers.
The CPU interacts with RAM via the memory controller, a chipset that manages data transactions between the CPU and RAM. This controller plays a critical role in managing access times and optimizing the flow of data.
The system can use a portion of the hard drive (or SSD) as virtual memory (see below).
Virtual Memory
Virtual Memory is a technique that extends RAM capacity by using part of the hard disk or SSD as additional memory. When RAM is full, data is swapped between RAM and virtual memory, allowing the system to run larger applications.
✅ Paging
- RAM and programs are divided into fixed-size blocks called pages.
- Only needed pages are loaded into RAM.
- Unused pages are moved to the HDD/SSD (Swap Space).
- Benefit: Allows running programs larger than physical RAM.
❌ Disk Thrashing
- Occurs when the system spends more time swapping pages than executing instructions.
- Cause: Too many open programs (RAM overload).
- Result: Major performance slowdown and high disk usage.
Analogy: The Desk & Backpack
"If you only have a small desk (RAM) and too many open books, you keep swapping books in/out of your backpack (HDD). You spend more time swapping than reading — that's thrashing!"
Read-Only Memory (ROM)
ROM is non-volatile memory containing the firmware or BIOS necessary for the initial booting of the computer. The CPU accesses this read-only data at startup to load the operating system from secondary storage (HDD/SSD) into RAM.
Cache Miss vs. Cache Hit
The CPU first checks Registers → L1 → L2 → L3 → RAM.
The CPU finds the data it needs in a cache. This is the fastest case.
The data is not found in cache. The CPU must fetch from slower main memory.
Minimizing Cache Misses
- Prefetching: Predicting and checking data before it is needed.
- Memory Allocation: OS allocates data based on usage patterns to maximize hits.
- Cache Replacement Policies: Intelligent decisions on what data to evict when cache is full (e.g., LRU).